Monocular Depth Estimation
Published:
1. 利用双目立体视觉的空间约束
left/right image作为各自的监督信号
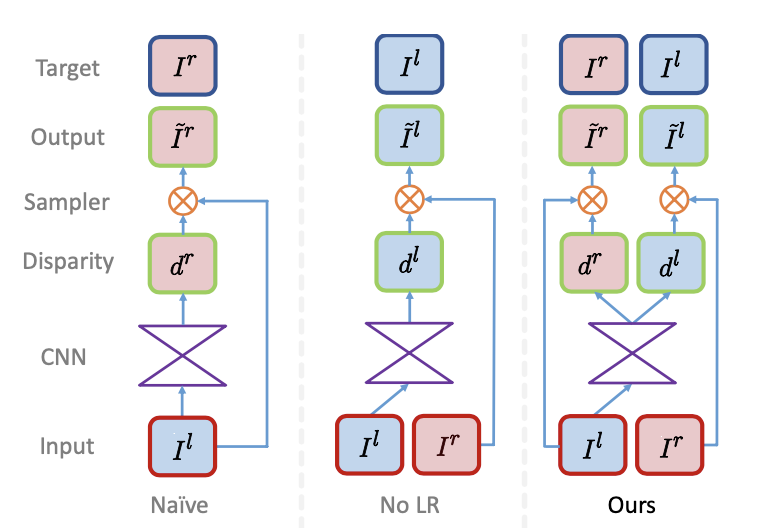
1.1. 《Unsupervised Monocular Depth Estimation with Left-Right Consistency》
Method:利用获得的左右两张图片,分别作为各自的监督信号,训练两获得视差图,计算合成图的loss。利用计算视差,通过视差计算得到深度
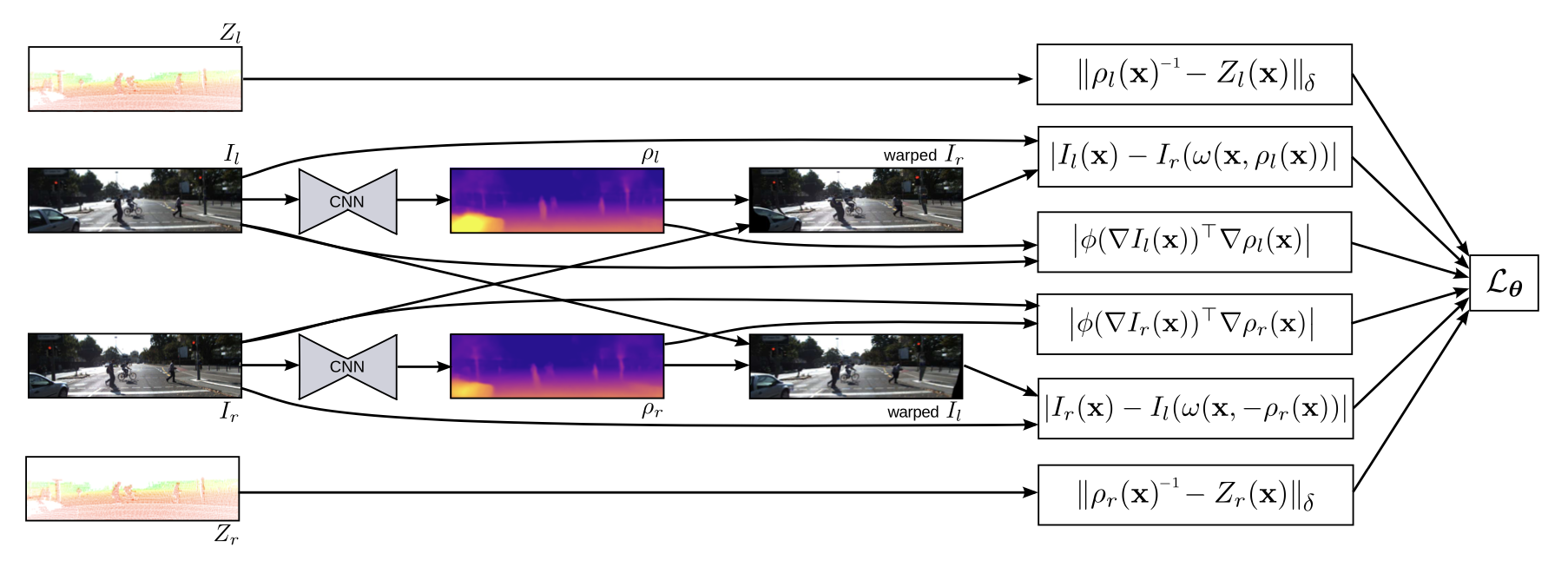
1.2. 《Semi-Supervised Deep Learning for Monocular Depth Map Prediction》——无代码
半监督:监督loss+无监督loss+smoothness loss
- 监督:左右图各自预测的depth(和sparse depth去)计算loss(在sparse depth有值的区域)
- 无监督:预测的depth和单视图,通过相机内参转换到另一视图,计算warp视图的loss(间接监督了depth)
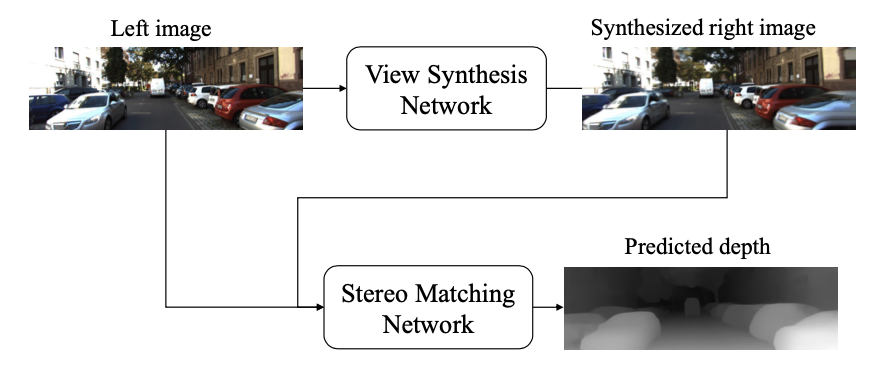
1.3. 《Single View Stereo Matching》2018
把depth estimation分解为:view synthesis+stereo matching两个步骤去做
Method:
- depth estimation可以被分解为两个问题:
view synthesis+stereo matching - 结合view synthesis(从左视图预测右视),并计算视差图,进而计算得深度图
view synthesis:采用视差概率图加权(预测每个视差值下的概率,加权得到最终的视差图,生成右视图,使得loss对其可导,能用神经网络训练)stereo matching:采用DispNetC(其中的1D correlation layer)和DispFullNet
2. 利用视频相邻帧作为监督信号
预测相机位姿和depth
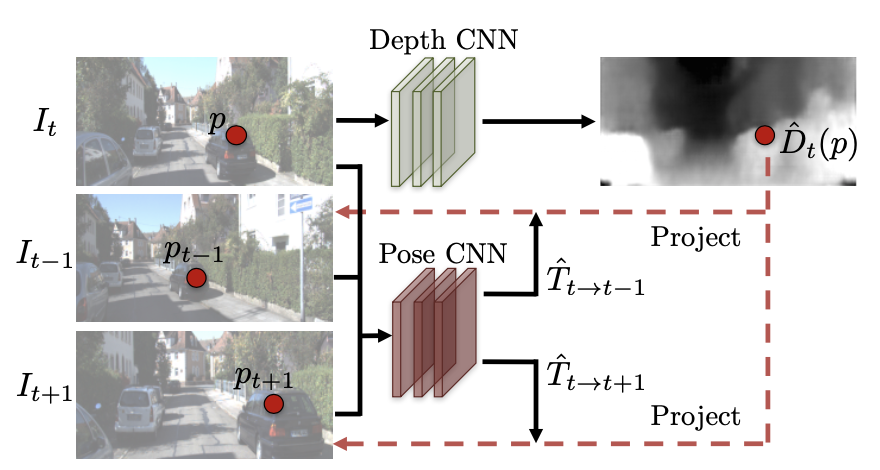
2.1.《Unsupervised Learning of Depth and Ego-Motion from Video》
Method:
- 前后帧和当前帧,通过
pose CNN的方法来预测pose的参数,再把相邻帧warp到当前帧(过程中使用到depth CNN预测得到的depth作为输入),计算合成的视图的像素之间的loss。【前后帧的3D坐标转换关系为PnP算法获得,再映射到图像坐标系】 - 提出使用
explainability mask来识别场景中运动的物体、遮挡或消失的物体(这些物体是和相机位姿变换规律违背的,无法预测的,所以让这些物体的像素产生的loss降低)
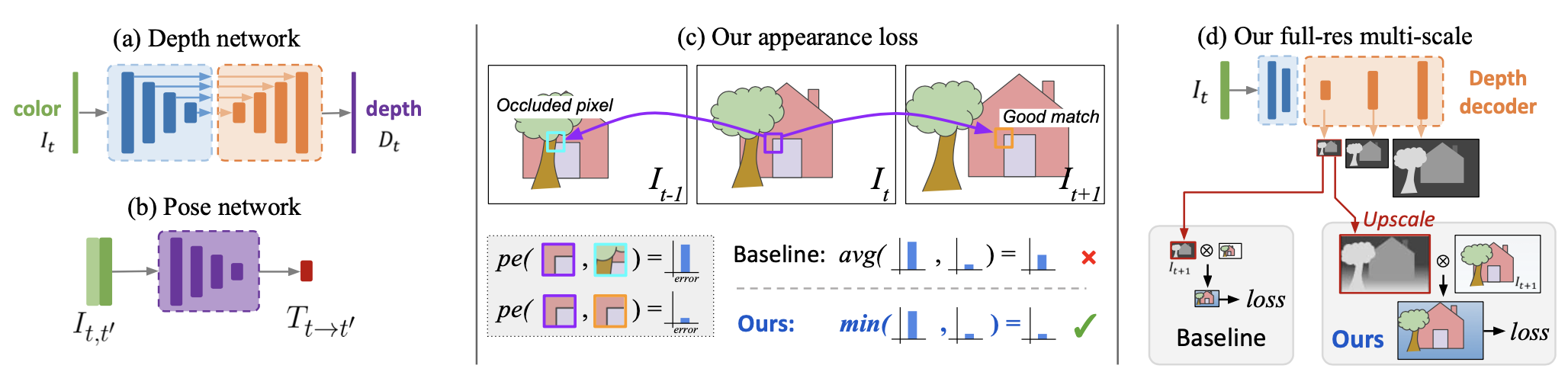
2.2. 《Digging Into Self-Supervised Monocular Depth Estimation》2019
- 提出了
minimum reprojection loss代替average loss代替对前后帧获得的loss取平均的策略【解决遮挡问题】 - 一个
full-resolution multi-scale的采样方法(对每个level的depth map都upsample到输入分辨率的尺寸去做reproject):【解决visual artifacts(视觉假象)】 - 一个
auto-masking loss(对图像中相对静止或静止的像素mask取0) 【忽视和camera motion假设的相反的像素】
3. 结合表面法向量联合训练
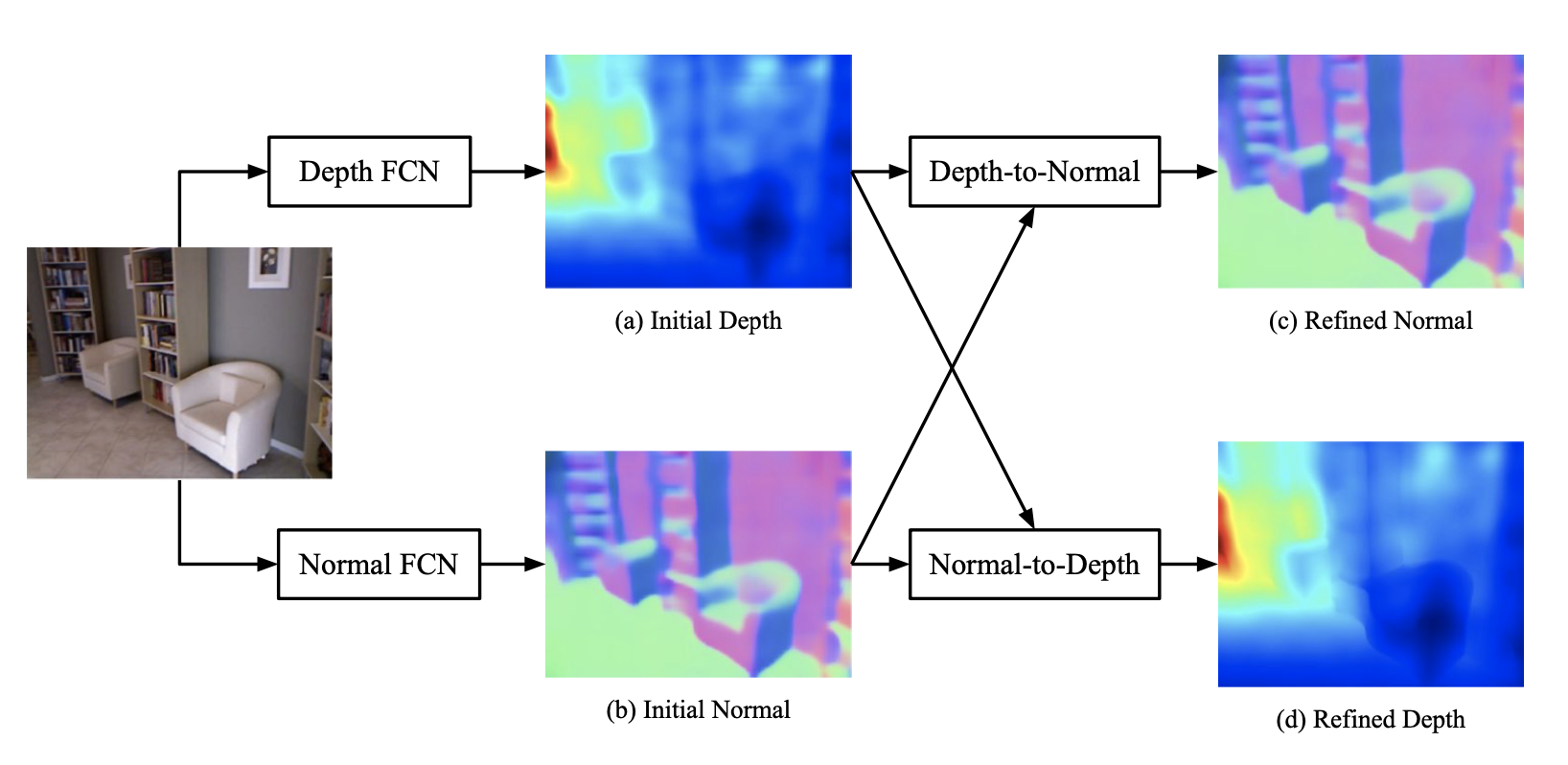
3.1. 《GeoNet: Geometric Neural Network》
Method:
- 提出使用
depth和normal联合训练,同时从单张图片预测normal和depth - Depth-to-Normal:由于直接用
CNN以图像为输入预测depth是有缺陷的(无法考虑到像素点之间的几何约束),所以提出使用粗糙的normal来联合depth去预测refined normal。 - Normal-to-Depth:使用核函数,去从normal和depth计算refined depth
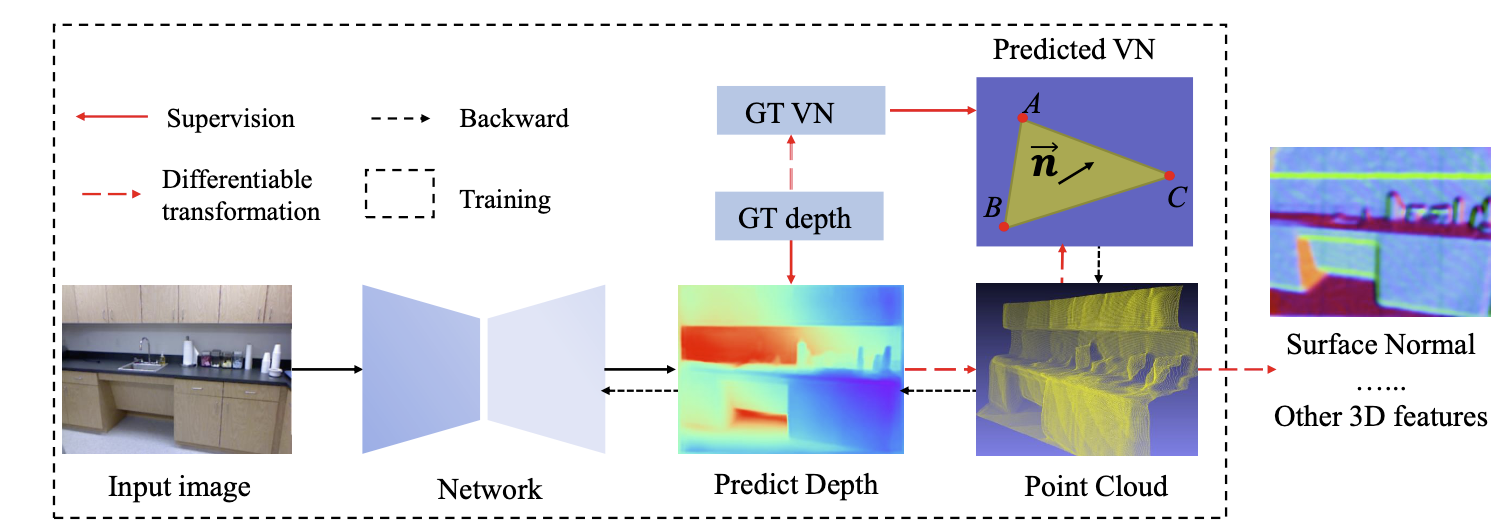
3.2. 2019-《Enforcing geometric constraints of virtual normal for depth prediction》
Method:
- 改进surface normal,提出virtual normal【相⽐比 surface normal(选取的⽤用于计算normal的平⾯面的local patch太⼩小,并且由于3D点云的噪声点对其影响 很⼤大),virtual normal由于特殊的设定,能够对local patch和3D点云噪声有鲁棒性】
5. 结合运动和边缘信息联合训练
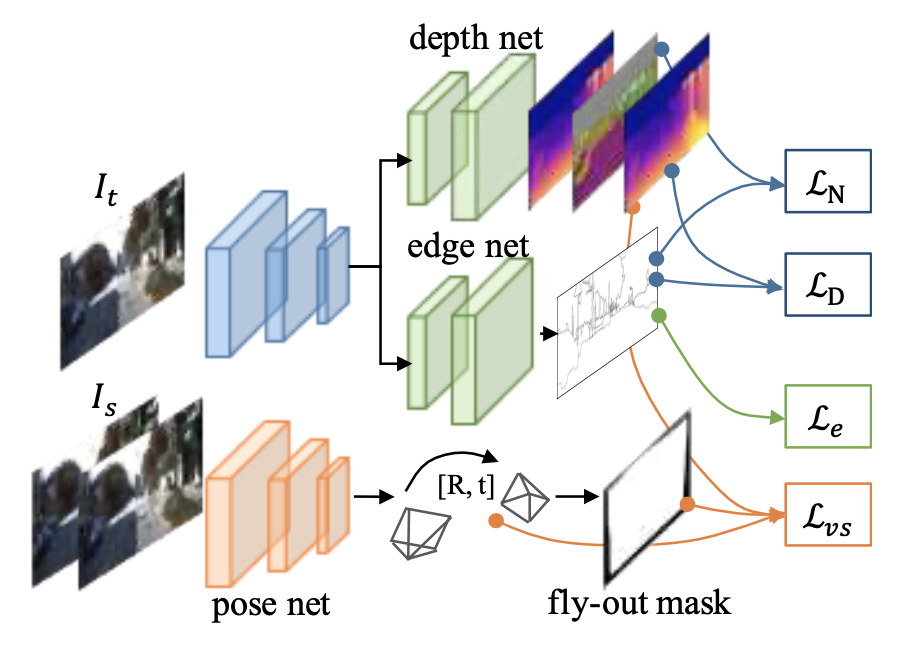
5.1. 《LEGO: Learning Edge with Geometry all at Once by Watching Videos》2018
(论文有点难看懂,以后再看)
6. 利用分割作为attention联合depth来训练
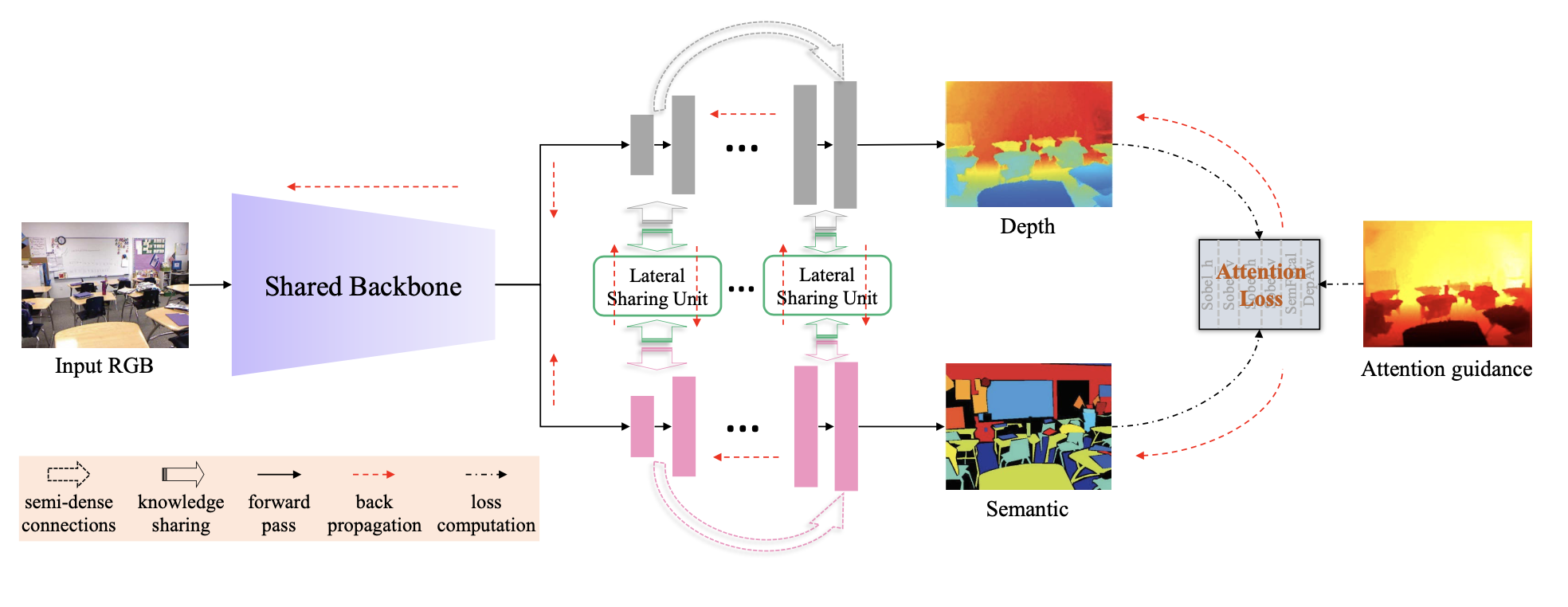
6.1. 《Look Deeper into Depth: Monocular Depth Estimation with Semantic Booster and Attention-Driven Loss》2018
- 分析数据集
depth的分布,提出更多关注正样本的loss - 提出使用语义分割和depth预测的loss【更多中心在loss这一块】
- 设计网络结构:融合depth和semantic的特征
7. 改进Loss
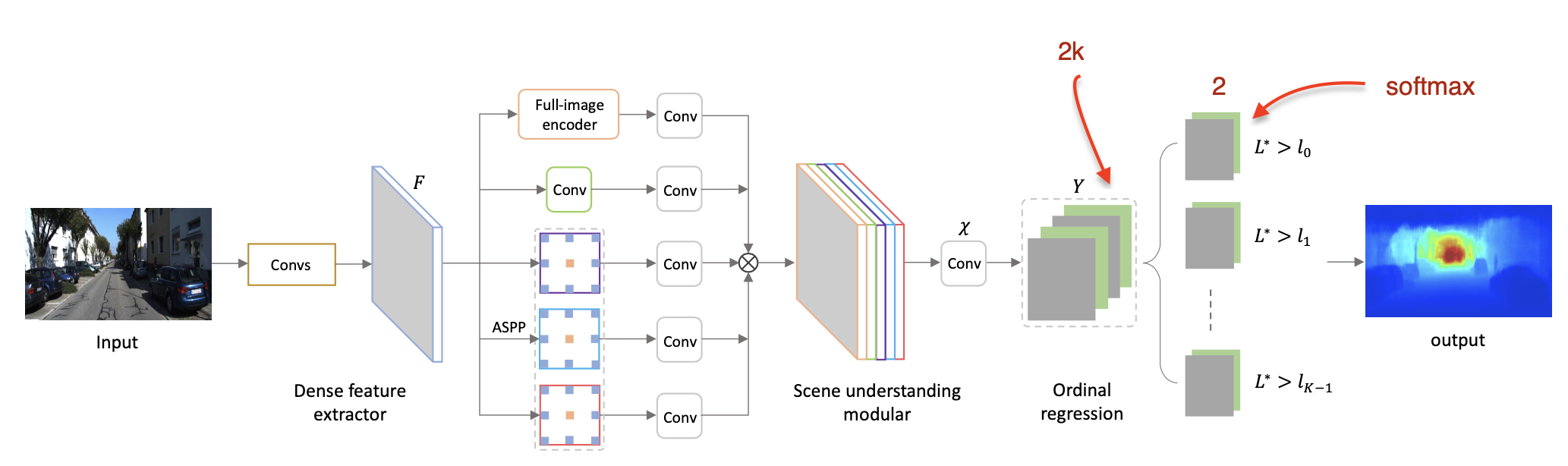
7.1. 《Deep Ordinal Regression Network for Monocular Depth Estimation》2018
【使用Ordinal Loss代替MSE Loss】
- 当前的网络的问题:
- 使用MSE作为loss:slow convergence/ unsatisfactory local solutions
- 复杂的网络(为了获得high-resolution的depth map):skip-connections/multi-layer deconv
- Method
- spacing-increasing discretization(SID) strategy:离散depth并recast【depth prediction的不确定性随着depth的增加而增加(远距离,depth的预测范围更大),所以在预测larger depth时需要允许相对更大的error,来避免larger depth差值的影响产生更大的影响。】
- 采用multi-scale network(ASPP模块):避免使用spatial pooling 或 并行地使用多尺度特征